
티스토리 뷰
이번 포스팅에서는 DQN으로 알려진 논문 Human-level control through deep reinforcement learning 논문에 대해서 리뷰하는 시간을 가져보겠습니다. 이번 포스팅에서 나오는 모든 이미지의 저작권은 위 논문의 저자에게 있습니다.
Nature에 2015년에 발표된 논문이고 저자는 DeepMind의 Volodymyr Minih입니다.
제목을 보면 "Deep Reinforcement Learning을 통해 Human Level의 Control이 가능하다"라고 볼 수 있습니다.
그러면 어떤 일에서 어떤 강화학습을 통해 얼만큼 가능한지 살펴보도록 하겠습니다.
1. Introduction
강화학습은 Agent가 환경에서 어떤 행동을 해야하는지에 대해 최적화 하는 방법을 제공합니다.
많은 강화학습 알고리즘은 간단한 State 정보만 가진 도메인에 대해서 성공적이었으나 Real World의 복잡한 환경에 대한 최적화는 여전히 어려운 문제입니다. 이 논문에서는 Atari 게임을 강화학습으로 학습하여 몇몇 게임에서 사람보다 높은 점수를 획득하는 결과를 보여줍시다.
이 논문에서 제시하는 Contribution은 총 3가지 인데
1. Deep Learning과 강화학습의 접목입니다. 따라서 고차원의 State 정보도 해석이 가능해졌습니다.
2. Experience Replay(Replay Memory)를 통해 Data Correlation 문제를 해결하였습니다.
3. Target-Q Network를 고정함으로 Network의 불안정성을 해결하였습니다.
아래 사진은 DQN 알고리즘의 Overview 입니다. 입력으로 현재 게임화면을 받아 네트워크를 지난 뒤 현재 프레임에서 어떤 Action을 해야할지 결과로 알려주게 됩니다.

2. Key Idea
다음으로 Contribution과 관련한 Key Idea에 대해서 설명해보도록 하겠습니다.
2.1 Correlation 문제
이전 강화학습의 문제점 중 하나는 Correlation Between Samples 이라는 문제가 있었습니다. Model 전체를 알고 있다면(아래 그림의 맨 왼쪽) 상관이 없지만 Model을 모를 때, 즉 자신의 경험만이 학습 Data가 될 때는 경험에 의해서 최적의 Policy를 찾아야 합니다. 하지만 아래 그림의 가운데와 같이 나의 경험 Data만을 가지고 학습을 하게 되면 이상한 모양의 선을 찾게 됩니다.

이러한 문제를 해결하기 위해서 이 논문에서는 Experience Replay(Replay Memory)라는 것을 사용합니다. 즉 이전의 경험들을 저장해두는 메모리를 만들어 저장을 한 뒤, 학습할 때 꺼내서 학습하는 것입니다. 이렇게 되면 Correlation이 적어지게 되고 제대로 학습할 수 있게 됩니다.

2.2 Network의 불안정성 문제
다음 문제는 Target 값이 안정되어 있지 않다는 문제가 있습니다. 아래 식을 보면 Loss를 정할 때 자기 자신이 Target이 됨으써 학습이 매우 불안정해지게 됩니다.

이 수식을 도식화 하게 되면 아래 그림과 같아집니다. 이렇게 되면 Network가 계속 Update 되면서 그때마다 최고의 Q값을 계산하므로 불안정해지게 됩니다.
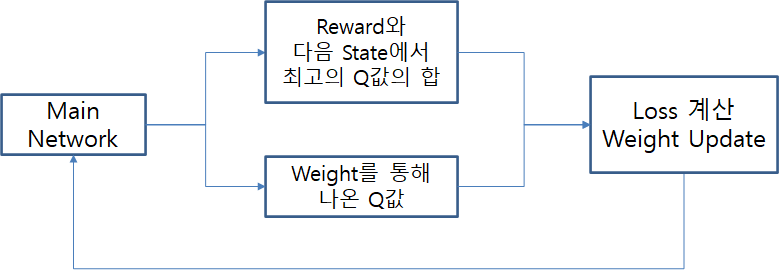
따라서 위의 모습을 Target Network를 새로 생성하여 아래와 같은 모습으로 바꾸어 줍니다. 이렇게 되면 매번 Update된 Main Network가 Target이 되는 것이 아니라 일정 기간마다 복사를 해오기 때문에 안정적인 학습이 가능해집니다.

2.3 Convolutional Neural Network를 활용한 Deep Q-Network
Deep Learning이 발전하기 전에는 Low Level의 State만 받아왔었지만 하드웨어의 발전과 알고리즘의 발전으로 인해 아래 그림과 같이 화면 전체의 Pixel을 State로 받아오는 것이 가능해졌고, 그렇기 때문에 Action을 결정할 수 있는 정보가 많아지고 더 정확한 결정을 할 수 있게 되었습니다.

3. Method
이제 실제로 DQN 알고리즘이 어떻게 진행되는지 설명해보도록 하겠습니다.
3.1 Data Pre-Processing
Pre-Processing을 거치지 않은 Data는 아래 그림과 같이 210*160 pixel과 128 color palette를 가지고 있었습니다. 따라서 많은 메모리와 계산이 필요했기 때문에 이 부분을 줄이고자 Pre-Processing을 진행하였습니다. 결과적으로 84*84 pixel 크기의 Gray Data로 변경하여 용량을 줄였습니다.

또한, 불필요한 Data를 줄이기 위해 아래 그림과 같이 k번째 frame만 남기고 나머지는 Skip하였습니다. 이 논문에서는 k를 4로 두어 4번째 frame만 학습에 사용하였습니다.

마지막으로 아래 그림과 같이 정해진 프레임의 바로 앞 프레임과 Pixel-wise maximum을 취해줍니다. 이 과정을 하는 이유는 Atari Game이 한 화면에 표시할 수 있는 sprites가 5개 밖에 되지 않아서 짝수 프레임과 홀 수 프레임에 번 갈아서 표시하는 방법을 사용했습니다. 그래서 이전 프레임을 가져와 pixel wise maximum을 취해주면 한 이미지에 모든 걸 표현할 수 있게 됩니다.

이렇게 만든 이미지가 하나의 State가 됩니다. 이렇게 만든 State를 M개씩 쌓아 하나의 State 뭉치를 만들면 그것이 입력으로 사용되는 State가 됩니다. M개씩 쌓는 이유는 현재의 움직임의 방향을 알기 위해서 쌓았습니다. 논문에서는 M을 4로 두었습니다. 따라서 한 State는 84x84x4 사이즈를 가지는 State가 됩니다.

3.2 Model Architecture
모델의 전체적인 Architecture는 아래 그림과 같습니다. 총 3가지의 Convolution Layer와 2개의 Fully connected Layer를 사용하였습니다.

3.3 Algorithm
Algorithm의 특징으로
1. Model Free 이며, Action Value Function을 사용하였습니다.
2. Off policy 이며, Q-Learning Algorithm을 사용하였습니다.
3. e-greedy 방식을 사용하였습니다. 0~1 사이의 수를 Random으로 뽑아 미리 지정한 e 보다 크면 Max Q 값을 가지는
Action을 선택하고, 작으면 Random Action을 선택합니다.
4. Loss Function은 아래와 같이 설계하였습니다.

3.4 Training Details
1. 49개의 Atari 2600 Game들을 Same Network Architecture로 학습시켰습니다.
2. 전체 학습기간 5000만 Frame (38일 정도 소요)
3. 여러 목숨을 가진 게임은 마지막 생명이 죽을 때 Episode의 끝으로 표현하였습니다.
4. Hyper Parameter 및 Optimization Parameter 값은 5게임만 가지고 찾았습니다. (Pong, Breakout, Seaquest, Space
Invaders, Beam Rider) 모든 게임을 고려하자면 너무 많은 계산이 필요하여, 다른 게임들은 아래에 있는
Extended Data Table1 대로 고정되어있다.
5. Optimization(Gradient Descent – RMSProp 사용)
6. e-greedy에서 e 값을 1.0에서 100만 Frame 까지 0.1로 줄이고 0.1로 고정
7. Replay Memory = 최근의 100만 Frame 저장
8. 여러 게임을 같은 Model로 학습하기 위해 Reward Clipping을 하였습니다. Positive = +1 / Negative = -1 / Else = 0

3.5 Training Algorithm for Deep Q-Networks
알고리즘의 수도코드는 아래 그림과 같습니다. 순서대로 보면 아래와 같습니다.
1. Replay Memory를 초기화
2. Weight 초기화
3. Preprocessing
4. e-greedy 실행
5. Simulation 및 Preprocessing
6. Replay Memory에 저장 및 Random Sampling
7. Q값 Update
8. Loss를 구해 Main Network Weight Update
9. C step마다 Target Network Weight Update

3.6 Evaluation Procedure
평가는 2팀의 비교를 통해 진행하였습니다.
1. DQN Agent
DQN Agent의 제약 조건은 아래와 같습니다.
1. ε = 0.05로 설정
2. 10Hz 마다 Action을 취할 수 있음 -> 10Hz는 사람이 가장 빨리 Button을 누를 수 있는 시간
3. 5분간 게임 30 Episode의 평균 값을 결과로 사용
2. Human Tester
Human Tester의 제약 조건은 아래와 같습니다.
1. 일시 중지, 저장, 로드 불가
2. 오디오 출력 비활성화 – 감각입력이 시각만 있도록
3. 2시간 연습 후 5분 게임 20 Episode의 평균 값을 결과로 사용
4. Result
이제 위의 알고리즘으로 학습하고 평가방법으로 평가한 결과를 보면 아래와 같습니다. 실제로 사람보다 훨씬 뛰어난 결과를 보여준 게임도 있지만 그렇지 못한 게임도 있는 것을 확인할 수 있습니다. 좋은 결과를 낸 게임을 보면 목표가 단순하다는 특징이 있었고, 결과가 좋지 못한 게임은 세부 미션이 있는등의 복잡한 게임이 점수가 낮았습니다.

게임 중에 Value의 변화를 보게 되면 아래 그림과 같습니다. 위에 있는 Breakout 게임에서 처음에 학습을 못할 때는 Value가 낮지만 학습을 많이 진행했을 때, 공을 맵 위쪽으로 보내는 Skill을 터득하면서 Value가 높아지는 것을 확인할 수 있습니다. 또한 아래 게임도 이전 Frame 까지 분석하여 지금 공이 어디로 오고 있는지 판단하여, Action을 결정하는 모습을 보여줍니다.

Training 양에 따른 결과를 보면 아래 그림과 같습니다. Training 양이 늘어날 수록 Score가 상승하는 것을 확인할 수 있습니다.

마지막으로 KeyIdea를 적용했을 때와 안했을 때의 결과 비교는 아래 그림과 같습니다. Replay Memory를 사용했을 때와 안했을 때, Target Q를 사용했을 때와 안했을 때를 비교해보면 결과 차이가 확연히 보이는 것을 확인할 수 있습니다.

이렇게 이번 포스팅에서는 DQN 논문을 리뷰하는 시간을 가져보았습니다.
다음 포스팅에서는 강화학습에서 많이 사용하는 Monte Carlo Tree Search에 대해서 알아보고 그 알고리즘을 활용한 간단한 틱택토 게임을 만들어 보도록 하겠습니다.
'강화학습' 카테고리의 다른 글
| 수박 겉핥기 강화학습 - 내 머리를 강화하자 #3 (0) | 2020.09.22 |
|---|---|
| 수박 겉핥기 강화학습 - 내 머리를 강화하자 #1 (0) | 2020.09.02 |
| 수박 겉핥기 강화학습 - 내 머리를 강화하자 #0 (0) | 2020.09.02 |
- Total
- Today
- Yesterday
- opengl
- Transformation
- 강화학습
- 값 형식
- Scriptable Render Pipeline
- 루빅스큐브
- RubiksCube
- Mesh Processing
- Unreal
- Mesh
- 참조 형식
- SRP
- RL
- MeshProcessing
- CollisionDetection
- transform
- NDC
- perspective projection
- normalized device coordinate
- VTK
- value type
- BoundingBox
- reference type
- Unity
- Bounding Box
- C#
- collision detection
- AABB
- Bounding Volume Hierarchy
- 유니티
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |